分布式锁入门:为什么需要分布式锁、锁粒度、超时续约与应用场景
网上有很多分布式锁相关的文章,这里写了一个相对简洁易懂的版本。面向面试和日常工作场景,先把最常见的概念和边界讲清楚。
这篇文章我们先介绍一下分布式锁的基本概念。
为什么需要分布式锁?
在多线程环境中,如果多个线程同时访问并修改同一份共享资源(例如商品库存、外卖订单),且没有互斥、原子更新、乐观锁或唯一约束等保护,就可能出现数据不一致、重复处理、超卖等问题,影响程序的正确性和稳定性。
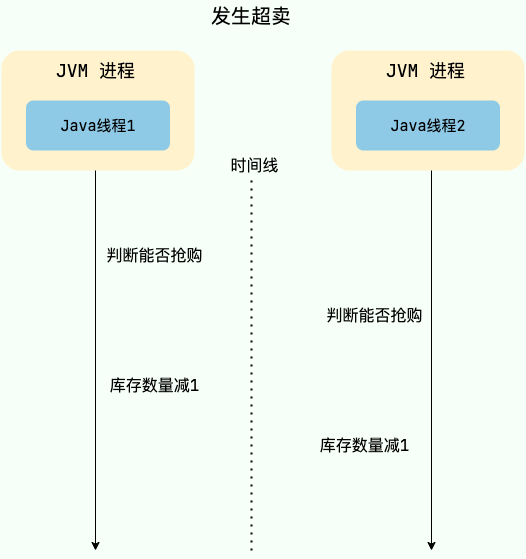
举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
- 线程 1、2、3 等多个线程同时进入抢购方法,每个线程对应一个用户。
- 线程 1 和线程 2 分别代表两个不同用户,它们几乎同时读到库存还剩 1 件,于是都通过库存校验,继续创建订单、扣减库存。
- 线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
- 线程 2 也继续执行,将库存数量减少 1 个,然后返回成功。
- 最终两个请求都成功,但库存只够卖 1 件,于是发生超卖。
这里的限购校验和库存扣减是两个不同的约束:限购主要解决同一用户重复购买的问题,库存扣减主要解决多个用户竞争同一份库存的问题。
锁的思路是把某段临界区串行化:同一时刻只允许一个执行单元进入这段逻辑。它能降低并发冲突,但也会牺牲吞吐;如果能用数据库原子更新、唯一约束、乐观锁、CAS 或消息串行化解决,就不一定要上分布式锁。
比如防超卖不一定要用分布式锁:数据库条件更新 UPDATE stock SET count = count - 1 WHERE sku_id = ? AND count > 0 可以保证库存不扣成负数;用户限购可以对 user_id + activity_id 建唯一索引;创建订单可以使用幂等键防重复提交。高并发场景还可以结合 Redis 预扣库存、MQ 异步落库和对账补偿。
这里讨论的分布式锁,本质上是一种悲观互斥方案:先拿到锁,再进入临界区,拿不到锁就等待、失败或重试。
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候都可能出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其他线程阻塞,用完后再把资源转让给其他线程。
对于单机多线程来说,在 Java 中,我们通常使用 ReentrantLock 类、synchronized 关键字这类 JDK 自带的 本地锁 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
下面是我对本地锁画的一张示意图。
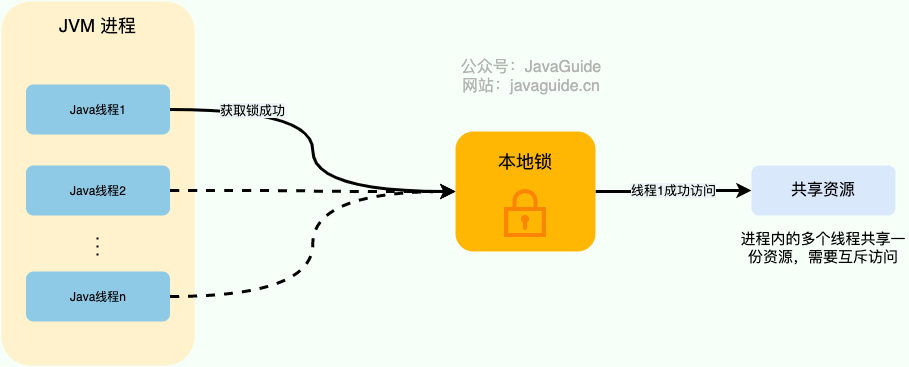
从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源,使用本地锁就没办法实现资源的互斥访问。这时就需要把锁的状态放到所有进程都能访问的外部系统中,也就是 分布式锁。
举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。为了防止超卖,需要保护的不是单独的“检查库存”,而是“校验库存 → 扣减库存 → 记录购买/创建订单”这段临界区;否则只锁查询、不锁扣减,仍然可能并发写错。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作。我们需要用到分布式锁,这样即使多个线程不在同一个 JVM 进程中,也能获取到同一把锁,进而实现共享资源的互斥访问。
下面是我对分布式锁画的一张示意图。
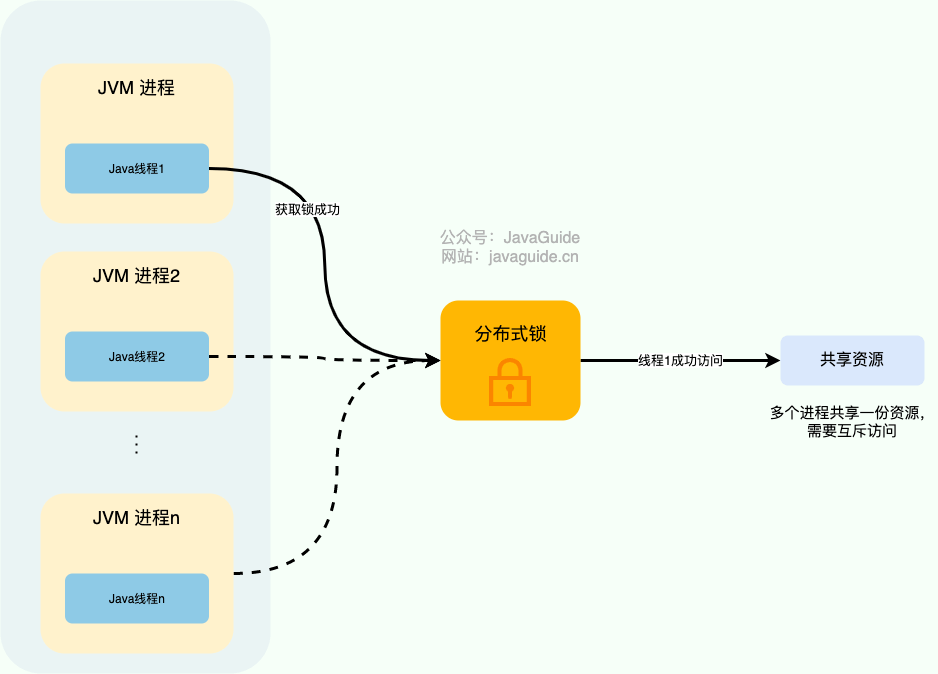
从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
分布式锁应该具备哪些条件?
一个最基本的分布式锁需要满足:
- 互斥:对同一个资源对应的同一个 lock key,同一时刻只能有一个有效持有者。lock key 要按资源粒度设计,例如
stock:{skuId}、order:{orderId},避免把无关资源都塞进一把全局大锁。 - 高可用和防死锁:锁服务本身要尽量可用;同时要有过期时间、会话机制或租约机制,避免客户端崩溃后锁永久不释放。但过期时间必须和业务执行时间、续约机制一起设计,否则可能出现锁提前过期、两个客户端同时进入临界区的问题。
- 安全释放:释放锁时必须校验锁持有者身份,只能释放自己持有的锁。以 Redis 为例,获取锁时写入随机 value,释放时用 Lua 脚本先比较 value,再删除 key。
除了上面这三个基本条件之外,一个好的分布式锁还需要满足下面这些条件:
- 可重入:不是所有场景都必须具备,但如果同一线程/请求链路可能重复进入同一临界区,就需要记录锁持有者和重入次数,避免自己把自己阻塞。
- 高性能:获取和释放锁的操作应该快速完成,并且不应该对整个系统的性能造成过大影响。
- 获取语义明确:获取锁可以是阻塞等待、限时等待,也可以是立即失败。生产中通常要设置最大等待时间和重试退避,不能无限等待。
- 续约机制:锁 TTL 要结合业务临界区的 P99 执行时间设置;临界区可能超过 TTL 时,需要看门狗/租约续约,或者缩短临界区。
- Fencing Token:更严格的场景还需要 Fencing Token。每次成功获取锁时生成一个单调递增 token,下游资源只接受 token 更大的写入,用来拦截锁过期后旧持有者的迟到写。
分布式锁的常见实现方式有哪些?
常见分布式锁实现方案如下:
- 基于关系型数据库比如 MySQL 实现分布式锁。
- 基于分布式协调服务 ZooKeeper 实现分布式锁。
- 基于 Redis 这类高性能键值存储(Key-Value Store),或 etcd 这类分布式一致性键值存储实现分布式锁。
数据库实现大致有三类:唯一索引插入锁表、基于事务的 SELECT ... FOR UPDATE 行锁、MySQL GET_LOCK() 这类命名锁。它们都能实现一定程度的互斥,但性能、释放时机、超时语义和故障恢复方式不同。
数据库方案不是不能做失效,而是失效语义和性能通常不如 Redis/ZooKeeper/etcd 这类方案自然。比如锁表可以加过期时间字段,但要处理过期锁抢占、时钟一致性、清理任务和事务隔离;GET_LOCK() 依赖 MySQL 连接/session 语义,不适合所有业务链路。
Redis 锁更常用于高性能、短临界区、允许通过业务幂等兜底的场景;ZooKeeper/etcd 更适合需要会话语义、顺序节点、租约和更强一致性的协调场景,但吞吐、延迟和运维成本通常更高。我专门写了一篇文章来详细介绍 Redis 和 ZooKeeper 这两种方案:分布式锁常见实现方案总结。
最后提醒一句:分布式锁不是分布式事务。锁只能控制临界区并发进入,不保证数据库提交一定成功,也不保证消息发送和订单写入原子一致。业务一致性仍要依赖本地事务、幂等、状态机、补偿任务等机制。
分布式锁面试怎么答?
面试可以按“为什么需要、怎么实现、有什么坑、如何兜底”来回答。
为什么需要:
- 单机锁只能保护一个 JVM 内的线程。
- 分布式部署后,同一业务资源可能被多个服务实例同时操作,需要跨进程互斥。
- 典型场景包括库存扣减、订单防重复处理、定时任务防多节点重复执行、缓存重建防击穿。
常见实现:
- Redis:使用
SET key value NX PX ttl获取锁,用 Lua 脚本校验 value 后删除锁。优点是性能好、实现简单;缺点是要处理 TTL、续约、主从切换和业务幂等。 - ZooKeeper:使用临时顺序节点实现锁,客户端会话断开后临时节点自动删除。优点是会话语义清晰、公平性更容易做;缺点是性能和运维成本相对更高。
- etcd:基于租约和事务机制实现锁,适合强一致协调场景。
- 数据库:可以用唯一索引、行锁、命名锁等方式实现,但通常吞吐和故障恢复语义不如专门的协调组件。
Redis 锁必须注意:
- 加锁要有过期时间,避免服务宕机后死锁。
- value 要用唯一随机值或 owner token,释放锁时只能释放自己的锁。
- 释放锁的“判断 value + 删除 key”要用 Lua 保证原子性。
- 业务执行时间可能超过 TTL 时,要有续约机制,或缩短临界区。
- 锁过期后旧持有者仍继续写入时,可能出现并发写错,严格场景要加 Fencing Token 或业务版本号。
兜底手段:
- 数据库唯一索引防重复。
- 状态机防止状态回退。
- 乐观锁/版本号防覆盖。
- 幂等表或业务幂等号防重复请求。
- 异常补偿和对账任务修复半成功状态。
总结
这篇文章我们主要介绍了:
- 分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
- 分布式锁应该具备的条件:互斥、高可用和防死锁、安全释放、可重入、高性能、获取语义明确、续约机制。更严格的场景还要配合 Fencing Token。
- 分布式锁的常见实现方式:关系型数据库比如 MySQL、分布式协调服务 ZooKeeper、Redis 这类高性能键值存储、etcd 这类分布式一致性键值存储。